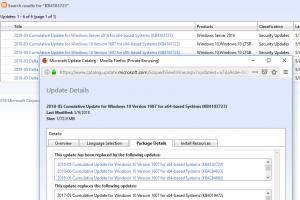
Лекция №4. Сжатие информации
Принципы сжатия информации
Цель сжатия данных - обеспечить компактное представление данных, вырабатываемых источником, для их более экономного сохранения и передачи по каналам связи.
Пусть у нас имеется файл размером 1 (один) мегабайт. Нам необходимо получить из него файл меньшего размера. Ничего сложного - запускаем архиватор, к примеру, WinZip, и получаем в результате, допустим, файл размером 600 килобайт. Куда же делись остальные 424 килобайта?
Сжатие информации является одним из способов ее кодирования. Вообще коды делятся на три большие группы - коды сжатия (эффективные коды), помехоустойчивые коды и криптографические коды. Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями. Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации. Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Виды сжатия
Все методы сжатия информации можно условно разделить на два больших непересекающихся класса: сжатие с потерей информации и сжатие без потери информации.
Сжатие без потери информации.
Эти методы сжатия нас интересуют в первую очередь, поскольку именно их применяют при передаче текстовых документов и программ, при выдаче выполненной работы заказчику или при создании резервных копий информации, хранящейся на копьютере.
Методы сжатия этого класса не могут допустить утрату информации, поэтому они основаны только на устранении ее избыточности, а информация имеет избыточность почти всегда (правда, если до этого кто-то ее уже не уплотнил). Если бы избыточности не было, нечего было бы и сжимать.
Вот простой пример. В русском языке 33 буквы, десять цифр и еще примерно полтора десятка знаков препинания и прочих специальных символов. Для текста, который записан только прописными русскими буквами (как в телеграммах и радиограммах) вполне хватило бы шестидесяти разных значений. Тем не менее, каждый символ обычно кодируется байтом, который содержит 8 битов и может выражать 256 различных кодов. Это первое основание для избыточности. Для нашего «телеграфного» текста вполне хватило бы шести битов на символ.
Вот другой пример. В международной кодировке символов ASCII для кодирования любого символа отводится одинаковое количество битов (8), в то время как всем давно и хорошо известно, что наиболее часто встречающиеся символы имеет смысл кодировать меньшим количеством знаков. Так, например, в «азбуке Морзе» буквы «Е» и «Т», которые встречаются часто, кодируются одним знаком (соответственно это точка и тире). А такие редкие буквы, как «Ю» ( - -) и «Ц» (- - ), кодируются четырьмя знаками. Неэффективная кодировка - второе основание для избыточности. Программы, выполняющие сжатие информации, могут вводить свою кодировку (разную для разных файлов) и приписывать к сжатому файлу некую таблицу (словарь), из которой распаковывающая программа узнает, как в данном файле закодированы те или иные символы или их группы. Алгоритмы, основанные на перекодировании информации, называют алгоритмами Хафмана.
Наличие повторяющихся фрагментов - третье основание для избыточности. В текстах это встречается редко, но в таблицах и в графике повторение кодов - обычное явление. Так, например, если число 0 повторяется двадцать раз подряд, то нет смысла ставить двадцать нулевых байтов. Вместо них ставят один ноль и коэффициент 20. Такие алгоритмы, основанные на выявлении повторов, называют методами RLE (Run Length Encoding ).
Большими повторяющимися последовательностями одинаковых байтов особенно отличаются графические иллюстрации, но не фотографические (там много шумов и соседние точки существенно различаются по параметрам), а такие, которые художники рисуют «гладким» цветом, как в мультипликационных фильмах.
Сжатие с потерей информации.
Сжатие с потерей информации означает, что после распаковки уплотненного архива мы получим документ, который несколько отличается от того, который был в самом начале. Понятно, что чем больше степень сжатия, тем больше величина потери и наоборот.
Разумеется, такие алгоритмы неприменимы для текстовых документов, таблиц баз данных и особенно для программ. Незначительные искажения в простом неформатированном тексте еще как-то можно пережить, но искажение хотя бы одного бита в программе сделает ее абсолютно неработоспособной.
В то же время, существуют материалы, в которых стоит пожертвовать несколькими процентами информации, чтобы получить сжатие в десятки раз. К ним относятся фотографические иллюстрации, видеоматериалы и музыкальные композиции. Потеря информации при сжатии и последующей распаковке в таких материалах воспринимается как появление некоторого дополнительного «шума». Но поскольку при создании этих материалов определенный «шум» все равно присутствует, его небольшое увеличение не всегда выглядит критичным, а выигрыш в размерах файлов дает огромный (в 10-15 раз на музыке, в 20-30 раз на фото- и видеоматериалах).
К алгоритмам сжатия с потерей информации относятся такие известные алгоритмы как JPEG и MPEG. Алгоритм JPEG используется при сжатии фотоизображений. Графические файлы, сжатые этим методом, имеют расширение JPG. Алгоритмы MPEG используют при сжатии видео и музыки. Эти файлы могут иметь различные расширения, в зависимости от конкретной программы, но наиболее известными являются.MPG для видео и.МРЗ для музыки.
Алгоритмы сжатия с потерей информации применяют только для потребительских задач. Это значит, например, что если фотография передается для просмотра, а музыка для воспроизведения, то подобные алгоритмы применять можно. Если же они передаются для дальнейшей обработки, например для редактирования, то никакая потеря информации в исходном материале недопустима.
Величиной допустимой потери при сжатии обычно можно управлять. Это позволяет экспериментовать и добиваться оптимального соотношения размер/качество. На фотографических иллюстрациях, предназначенных для воспроизведения на экране, потеря 5% информации обычно некритична, а в некоторых случаях можно допустить и 20-25%.
Алгоритмы сжатия без потери информации
Код Шеннона-Фэно
Для дальнейших рассуждений будет удобно представить наш исходный файл с текстом как источник символов, которые по одному появляются на его выходе. Мы не знаем заранее, какой символ будет следующим, но мы знаем, что с вероятностью p1 появится буква "а", с вероятностью p2 -буква "б" и т.д.
В простейшем случае мы будем считать все символы текста независимыми друг от друга, т.е. вероятность появления очередного символа не зависит от значения предыдущего символа. Конечно, для осмысленного текста это не так, но сейчас мы рассматриваем очень упрощенную ситуацию. В этом случае справедливо утверждение "символ несет в себе тем больше информации, чем меньше вероятность его появления".
Давайте представим себе текст, алфавит которого состоит всего из 16 букв: А, Б, В, Г, Д, Е, Ж, З, И, К, Л, М, Н, О, П, Р. Каждый из этих знаков можно закодировать с помощью всего 4 бит: от 0000 до 1111. Теперь представим себе, что вероятности появления этих символов распределены следующим образом:
Сумма этих вероятностей составляет, естественно, единицу. Разобьем эти символы на две группы таким образом, чтобы суммарная вероятность символов каждой группы составляла ~0.5 (рис). В нашем примере это будут группы символов А-В и Г-Р. Кружочки на рисунке, обозначающие группы символов, называются вершинами или узлами (nodes), а сама конструкция из этих узлов - двоичным деревом (B-tree). Присвоим каждому узлу свой код, обозначив один узел цифрой 0, а другой - цифрой 1.
Снова
разобьем первую группу (А-В) на две
подгруппы таким образом, чтобы их
суммарные вероятности были как можно
ближе друг к другу. Добавим к коду первой
подгруппы цифру 0, а к коду второй - цифру
1. 
Будем повторять эту операцию до тех пор, пока на каждой вершине нашего "дерева" не останется по одному символу. Полное дерево для нашего алфавита будет иметь 31 узел.
Коды символов (крайние правые узлы дерева) имеют коды неодинаковой длины. Так, буква А, имеющая для нашего воображаемого текста вероятность p=0.2, кодируется всего двумя битами, а буква Р (на рисунке не показана), имеющая вероятность p=0.013, кодируется аж шестибитовой комбинацией.
Итак, принцип очевиден - часто встречающиеся символы кодируются меньшим числом бит, редко встречающиеся - большим. В результате среднестатистическое количество бит на символ будет равно

где ni - количество бит, кодирующих i-й символ, pi - вероятность появления i-го символа.
Код Хаффмана.
Алгоритм Хаффмана изящно реализует общую идею статистического кодирования с использованием префиксных множеств и работает следующим образом:
1. Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте.
2. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагаем равной сумме вероятностей составляющих его символов. В конце концов построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него.
3. Прослеживаем путь к каждому листу дерева, помечая направление к каждому узлу (например, направо - 1, налево - 0) . Полученная последовательность дает кодовое слово, соответствующее каждому символу (рис.).
Построим кодовое дерево для сообщения со следующим алфавитом:

Недостатки методов
Самой большой сложностью с кодами, как следует из предыдущего обсуждения, является необходимость иметь таблицы вероятностей для каждого типа сжимаемых данных. Это не представляет проблемы, если известно, что сжимается английский или русский текст; мы просто предоставляем кодеру и декодеру подходящее для английского или русского текста кодовое дерево. В общем же случае, когда вероятность символов для входных данных неизвестна, статические коды Хаффмана работают неэффективно.
Решением этой проблемы является статистический анализ кодируемых данных, выполняемый в ходе первого прохода по данным, и составление на его основе кодового дерева. Собственно кодирование при этом выполняется вторым проходом.
Еще один недостаток кодов - это то, что минимальная длина кодового слова для них не может быть меньше единицы, тогда как энтропия сообщения вполне может составлять и 0,1, и 0,01 бит/букву. В этом случае код становится существенно избыточным. Проблема решается применением алгоритма к блокам символов, но тогда усложняется процедура кодирования/декодирования и значительно расширяется кодовое дерево, которое нужно в конечном итоге сохранять вместе с кодом.
Данные коды никак не учитывают взаимосвязей между символами, которые присутствуют практически в любом тексте. Например, если в тексте на английском языке нам встречается буква q, то мы с уверенностью сможем сказать, что после нее будет идти буква u.
Групповое кодирование - Run Length Encoding (RLE) - один из самых старых и самых простых алгоритмов архивации. Сжатие в RLE происходит за счет замены цепочек одинаковых байт на пары "счетчик, значение". («красный, красный, ..., красный» записывается как «N красных»).
Одна из реализаций алгоритма такова: ищут наименнее часто встречающийся байт, называют его префиксом и делают замены цепочек одинаковых символов на тройки "префикс, счетчик, значение". Если же этот байт встретичается в исходном файле один или два раза подряд, то его заменяют на пару "префикс, 1" или "префикс, 2". Остается одна неиспользованная пара "префикс, 0", которую можно использовать как признак конца упакованных данных.
При кодировании exe-файлов можно искать и упаковывать последовательности вида AxAyAzAwAt..., которые часто встречаются в ресурсах (строки в кодировке Unicode)
К положительным сторонам алгоритма, можно отнести то, что он не требует дополнительной памяти при работе, и быстро выполняется. Алгоритм применяется в форматах РСХ, TIFF, ВМР. Интересная особенность группового кодирования в PCX заключается в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
LZW-код (Lempel-Ziv & Welch) является на сегодняшний день одним из самых распространенных кодов сжатия без потерь. Именно с помощью LZW-кода осуществляется сжатие в таких графических форматах, как TIFF и GIF, с помощью модификаций LZW осуществляют свои функции очень многие универсальные архиваторы. Работа алгоритма основана на поиске во входном файле повторяющихся последовательностей символов, которые кодируются комбинациями длиной от 8 до 12 бит. Таким образом, наибольшую эффективность данный алгоритм имеет на текстовых файлах и на графических файлах, в которых имеются большие одноцветные участки или повторяющиеся последовательности пикселов.
Отсутствие потерь информации при LZW-кодировании обусловило широкое распространение основанного на нем формата TIFF. Этот формат не накладывает каких-либо ограничений на размер и глубину цвета изображения и широко распространен, например, в полиграфии. Другой основанный на LZW формат - GIF - более примитивен - он позволяет хранить изображения с глубиной цвета не более 8 бит/пиксел. В начале GIF - файла находится палитра - таблица, устанавливающая соответствие между индексом цвета - числом в диапазоне от 0 до 255 и истинным, 24-битным значением цвета.
Алгоритмы сжатия с потерей информации
Алгоритм JPEG был разработан группой фирм под названием Joint Photographic Experts Group. Целью проекта являлось создание высокоэффективного стандарта сжатия как черно-белых, так и цветных изображений, эта цель и была достигнута разработчиками. В настоящее время JPEG находит широчайшее применение там, где требуется высокая степень сжатия - например, в Internet.
В отличие от LZW-алгоритма JPEG-кодирование является кодированием с потерями. Сам алгоритм кодирования базируется на очень сложной математике, но в общих чертах его можно описать так: изображение разбивается на квадраты 8*8 пикселов, а затем каждый квадрат преобразуется в последовательную цепочку из 64 пикселов. Далее каждая такая цепочка подвергается так называемому DCT-преобразованию, являющемуся одной из разновидностей дискретного преобразования Фурье. Оно заключается в том, что входную последовательность пикселов можно представить в виде суммы синусоидальных и косинусоидальных составляющих с кратными частотами (так называемых гармоник). В этом случае нам необходимо знать лишь амплитуды этих составляющих для того, чтобы восстановить входную последовательность с достаточной степенью точности. Чем большее количество гармонических составляющих нам известно, тем меньше будет расхождение между оригиналом и сжатым изображением. Большинство JPEG-кодеров позволяют регулировать степень сжатия. Достигается это очень простым путем: чем выше степень сжатия установлена, тем меньшим количеством гармоник будет представлен каждый 64-пиксельный блок.
Безусловно, сильной стороной данного вида кодирования является большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило его широкое применение в Internet, где уменьшение размера файлов имеет первостепенное значение, в мультимедийных энциклопедиях, где требуется хранение возможно большего количества графики в ограниченном объеме.
Отрицательным свойством этого формата является неустранимое никакими средствами, внутренне ему присущее ухудшение качества изображения. Именно этот печальный факт не позволяет применять его в полиграфии, где качество ставится во главу угла.
Однако формат JPEG не является пределом совершенства в стремлении уменьшить размер конечного файла. В последнее время ведутся интенсивные исследования в области так называемого вейвлет-преобразования (или всплеск-преобразования). Основанные на сложнейших математических принципах вейвлет-кодеры позволяют получить большее сжатие, чем JPEG, при меньших потерях информации. Несмотря на сложность математики вейвлет-преобразования, в программной реализации оно проще, чем JPEG. Хотя алгоритмы вейвлет-сжатия пока находятся в начальной стадии развития, им уготовано большое будущее.
Фрактальное сжатие
Фрактальное сжатие изображений - это алгоритм сжатия изображений c потерями, основанный на применении систем итерируемых функций (IFS, как правило являющимися аффинными преобразованиями) к изображениям. Данный алгоритм известен тем, что в некоторых случаях позволяет получить очень высокие коэффициенты сжатия (лучшие примеры - до 1000 раз при приемлемом визуальном качестве) для реальных фотографий природных объектов, что недоступно для других алгоритмов сжатия изображений в принципе. Из-за сложной ситуации с патентованием широкого распространения алгоритм не получил.
Фрактальная архивация основана на том, что с помощью коэффициентов системы итерируемых функций изображение представляется в более компактной форме. Прежде чем рассматривать процесс архивации, разберем, как IFS строит изображение.
Строго говоря, IFS - это набор трехмерных аффинных преобразований, переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (x координата, у координата, яркость).
Основа метода фрактального кодирования - это обнаружение самоподобных участков в изображении. Впервые возможность применения теории систем итерируемых функций (IFS) к проблеме сжатия изображения была исследована Майклом Барнсли и Аланом Слоуном. Они запатентовали свою идею в 1990 и 1991 гг. Джеквин (Jacquin) представил метод фрактального кодирования, в котором используются системы доменных и ранговых блоков изображения (domain and range subimage blocks), блоков квадратной формы, покрывающих все изображение. Этот подход стал основой для большинства методов фрактального кодирования, применяемых сегодня. Он был усовершенствован Ювалом Фишером (Yuval Fisher) и рядом других исследователей.
В соответствии с данным методом изображение разбивается на множество неперекрывающихся ранговых подизображений (range subimages) и определяется множество перекрывающихся доменных подизображений (domain subimages). Для каждого рангового блока алгоритм кодирования находит наиболее подходящий доменный блок и аффинное преобразование, которое переводит этот доменный блок в данный ранговый блок. Структура изображения отображается в систему ранговых блоков, доменных блоков и преобразований.
Идея заключается в следующем: предположим, что исходное изображение является неподвижной точкой некоего сжимающего отображения. Тогда можно вместо самого изображения запомнить каким-либо образом это отображение, а для восстановления достаточно многократно применить это отображение к любому стартовому изображению.
По теореме Банаха, такие итерации всегда приводят к неподвижной точке, то есть к исходному изображению. На практике вся трудность заключается в отыскании по изображению наиболее подходящего сжимающего отображения и в компактном его хранении. Как правило, алгоритмы поиска отображения (то есть алгоритмы сжатия) в значительной степени переборные и требуют больших вычислительных затрат. В то же время, алгоритмы восстановления достаточно эффективны и быстры.
Вкратце метод, предложенный Барнсли, можно описать следующим образом. Изображение кодируется несколькими простыми преобразованиями (в нашем случае аффинными), то есть определяется коэффициентами этих преобразований (в нашем случае A, B, C, D, E, F).
Например, изображение кривой Коха можно закодировать четырмя аффинными преобразованиями, мы однозначно определим его с помощью всего 24-х коэффициентов.
В результате точка обязательно перейдёт куда-то внутрь чёрной области на исходном изображении. Проделав такую операцию много раз, мы заполним все чёрное пространство, тем самым восстановив картинку.

Наиболее известны два изображения, полученных с помощью IFS: треугольник Серпинского и папоротник Барнсли. Первое задается тремя, а второе - пятью аффинными преобразованиями (или, в нашей терминологии, линзами). Каждое преобразование задается буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.
Становится понятно, как работает архиватор, и почему ему требуется так много времени. Фактически, фрактальная компрессия - это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований.
В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное число раз, не позволит добиться приемлемого времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Для фрактального алгоритма компрессии, как и для других алгоритмов сжатия с потерями, очень важны механизмы, с помощью которых можно будет регулировать степень сжатия и степень потерь. К настоящему времени разработан достаточно большой набор таких методов. Во-первых, можно ограничить количество преобразований, заведомо обеспечив степень сжатия не ниже фиксированной величины. Во-вторых, можно потребовать, чтобы в ситуации, когда разница между обрабатываемым фрагментом и наилучшим его приближением будет выше определенного порогового значения, этот фрагмент дробился обязательно (для него обязательно заводится несколько линз). В-третьих, можно запретить дробить фрагменты размером меньше, допустим, четырех точек. Изменяя пороговые значения и приоритет этих условий, можно очень гибко управлять коэффициентом компрессии изображения: от побитного соответствия, до любой степени сжатия.
Сравнение с JPEG
Сегодня наиболее распространенным алгоритмом архивации графики является JPEG. Сравним его с фрактальной компрессией.
Во-первых, заметим, что и тот, и другой алгоритм оперируют 8-битными (в градациях серого) и 24-битными полноцветными изображениями. Оба являются алгоритмами сжатия с потерями и обеспечивают близкие коэффициенты архивации. И у фрактального алгоритма, и у JPEG существует возможность увеличить степень сжатия за счет увеличения потерь. Кроме того, оба алгоритма очень хорошо распараллеливаются.
Различия начинаются, если мы рассмотрим время, необходимое алгоритмам для архивации/разархивации. Так, фрактальный алгоритм сжимает в сотни и даже в тысячи раз дольше, чем JPEG. Распаковка изображения, наоборот, произойдет в 5-10 раз быстрее. Поэтому, если изображение будет сжато только один раз, а передано по сети и распаковано множество раз, то выгодней использовать фрактальный алгоритм.
JPEG использует разложение изображения по косинусоидальным функциям, поэтому потери в нем (даже при заданных минимальных потерях) проявляются в волнах и ореолах на границе резких переходов цветов. Именно за этот эффект его не любят использовать при сжатии изображений, которые готовят для качественной печати: там этот эффект может стать очень заметен.
Фрактальный алгоритм избавлен от этого недостатка. Более того, при печати изображения каждый раз приходится выполнять операцию масштабирования, поскольку растр (или линиатура) печатающего устройства не совпадает с растром изображения. При преобразовании также может возникнуть несколько неприятных эффектов, с которыми можно бороться либо масштабируя изображение программно (для дешевых устройств печати типа обычных лазерных и струйных принтеров), либо снабжая устройство печати своим процессором, винчестером и набором программ обработки изображений (для дорогих фотонаборных автоматов). Как можно догадаться, при использовании фрактального алгоритма таких проблем практически не возникает.
Вытеснение JPEG фрактальным алгоритмом в повсеместном использовании произойдет еще не скоро (хотя бы в силу низкой скорости архивации последнего), однако в области приложений мультимедиа, в компьютерных играх его использование вполне оправдано.
Введение.
Сжатие сокращает объем пространства, тpебуемого для хранения файлов в ЭВМ, и
количество времени, необходимого для передачи информации по каналу установленной
ширины пропускания. Это есть форма кодирования. Другими целями кодирования
являются поиск и исправление ошибок, а также шифрование. Процесс поиска и
исправления ошибок противоположен сжатию - он увеличивает избыточность данных,
когда их не нужно представлять в удобной для восприятия человеком форме. Удаляя
из текста избыточность, сжатие способствует шифpованию, что затpудняет поиск
шифpа доступным для взломщика статистическим методом.
Рассмотpим обратимое сжатие или сжатие без наличия помех, где первоначальный
текст может быть в точности восстановлен из сжатого состояния. Необратимое или
ущербное сжатие используется для цифровой записи аналоговых сигналов, таких как
человеческая речь или рисунки. Обратимое сжатие особенно важно для текстов,
записанных на естественных и на искусственных языках, поскольку в этом случае
ошибки обычно недопустимы. Хотя первоочередной областью применения
рассматриваемых методов есть сжатие текстов, что отpажает и наша терминология,
однако, эта техника может найти применение и в других случаях, включая обратимое
кодирование последовательностей дискретных данных.
Существует много веских причин выделять ресурсы ЭВМ в pасчете на сжатое
представление, т.к. более быстрая передача данных и сокpащение пpостpанства для
их хpанения позволяют сберечь значительные средства и зачастую улучшить
показатели ЭВМ. Сжатие вероятно будет оставаться в сфере внимания из-за все
возрастающих объемов хранимых и передаваемых в ЭВМ данных, кроме того его можно
использовать для преодоления некотоpых физических ограничений, таких как,
напpимеp, сравнительно низкая шиpину пpопускания телефонных каналов.
ПРИМЕНЕНИЕ РАСШИРЯЮЩИХСЯ ДЕРЕВЬЕВ ДЛЯ СЖАТИЯ ДАННЫХ.
Алгоритмы сжатия могут повышать эффективность хранения и передачи данных
посредством сокращения количества их избыточности. Алгоритм сжатия берет в
качестве входа текст источника и производит соответствующий ему сжатый текст,
когда как разворачивающий алгоритм имеет на входе сжатый текст и получает из
него на выходе первоначальный текст источника. Большинство алгоритмов сжатия
рассматривают исходный текст как набор строк, состоящих из букв алфавита
исходного текста.
Избыточность в представлении строки S есть L(S) - H(S), где L(S) есть длина
представления в битах, а H(S) - энтропия - мера содержания информации, также
выраженная в битах. Алгоритмов, которые могли бы без потери информации сжать
строку к меньшему числу бит, чем составляет ее энтропия, не существует. Если из
исходного текста извлекать по одной букве некоторого случайного набоpа,
использующего алфавит А, то энтропия находится по формуле:
H(S) = C(S) p(c) log ---- ,
где C(S) есть количество букв в строке, p(c) есть статическая вероятность
появления некоторой буквы C. Если для оценки p(c) использована частота появления
каждой буквы c в строке S, то H(C) называется самоэнтропией строки S. В этой
статье H (S) будет использоваться для обозначения самоэнтропии строки, взятой из
статичного источника.
Расширяющиеся деревья обычно описывают формы лексикографической упорядоченности
деpевьев двоичного поиска, но деревья, используемые при сжатии данных могут не
иметь постоянной упорядоченности. Устранение упорядоченности приводит к
значительному упрощению основных операций расширения. Полученные в итоге
алгоритмы предельно быстры и компактны. В случае применения кодов Хаффмана,
pасширение приводит к локально адаптированному алгоритму сжатия, котоpый
замечательно прост и быстр, хотя и не позволяет достигнуть оптимального сжатия.
Когда он применяется к арифметическим кодам, то результат сжатия близок к
оптимальному и приблизительно оптимален по времени.
КОДЫ ПРЕФИКСОВ.
Большинство широко изучаемых алгоритмов сжатия данных основаны на кодах
Хаффмана. В коде Хаффмана каждая буква исходного текста представляется в архиве
кодом переменной длины. Более частые буквы представляются короткими кодами,
менее частые - длинными. Коды, используемые в сжатом тексте должны подчиняться
свойствам префикса, а именно: код, использованный в сжатом тексте не может быть
префиксом любого другого кода.
Коды префикса могут быть найдены посредством дерева, в котором каждый лист
соответствует одной букве алфавита источника. Hа pисунке 1 показано дерево кода
префикса для алфавита из 4 букв. Код префикса для буквы может быть прочитан при
обходе деpева от корня к этой букве, где 0 соответствует выбору левой его ветви,
а 1 - правой. Дерево кода Хаффмана есть дерево с выравненным весом, где каждый
лист имеет вес, равный частоте встречаемости буквы в исходном тексте, а
внутренние узлы своего веса не имеют. Дерево в примере будет оптимальным, если
частоты букв A, B, C и D будут 0.125, 0.125, 0.25 и 0.5 соответственно.
Обычные коды Хаффмана требуют предварительной информации о частоте встречаемости
букв в исходном тексте, что ведет к необходимости его двойного просмотра - один
для получения значений частот букв, другой для проведения самого сжатия. В
последующем, значения этих частот нужно объединять с самим сжатым текстом, чтобы
в дальнейшем сделать возможным его развертывание. Адаптивное сжатие выполняется
за один шаг, т.к. код, используемый для каждой буквы исходного текста, основан
на частотах всех остальных кpоме нее букв алфавита. Основы для эффективной
реализации адаптивного кода Хаффмана были заложены Галлагером, Кнут опубликовал
практическую версию такого алгоритма, а Уиттер его pазвил.
Оптимальный адаптированный код Уиттера всегда лежит в пределах одного бита на
букву источника по отношению к оптимальному статичному коду Хаффмана, что обычно
составляет несколько процентов от H . К тому же, статичные коды Хаффмана всегда
лежат в пределах одного бита на букву исходного текста от H (они достигают этот
предел только когда для всех букв p(C) = 2). Существуют алгоритмы сжатия
которые могут преодолевать эти ограничения. Алгоритм Зива-Лемпелла, например,
присваивает слова из аpхива фиксированной длины строкам исходного текста
пеpеменной длины, а арифметическое сжатие может использовать для кодирования
букв источника даже доли бита.
Применение расширения к кодам префикса.
Расширяющиеся деревья были впервые описаны в 1983 году и более подpобно
рассмотрены в 1985. Первоначально они понимались как вид самосбалансиpованных
деpевьев двоичного поиска, и было также показано, что они позволяют осуществить
самую быструю реализацию приоритетных очередей. Если узел расширяющегося дерева
доступен, то оно является расширенным. Это значит, что доступный узел становится
корнем, все узлы слева от него образуют новое левое поддерево, узлы справа -
новое правое поддерево. Расширение достигается при обходе дерева от старого
корня к целевому узлу и совершении пpи этом локальных изменений, поэтому цена
расширения пропорциональна длине пройденного пути.
Тарьян и Слейтон показали, что расширяющиеся деревья статично оптимальны.
Другими словами, если коды доступных узлов взяты согласно статичному
распределению вероятности, то скорости доступа к расширяющемуся дереву и
статично сбалансированному, оптимизированному этим распределением, будут
отличаться друг от друга на постоянный коэффициент, заметный при достаточно
длинных сериях доступов. Поскольку дерево Хаффмана представляет собой пример
статично сбалансированного дерева, то пpи использовании расширения для сжатия
данных, pазмер сжатого текста будет лежать в пределах некоторого коэффициента от
размера архива, полученного при использовании кода Хаффмана.
Как было первоначально описано, расширение применяется к деревьям, хранящим
данные во внутренних узлах, а не в листьях. Деревья же кодов префикса несут все
свои данные только в листьях. Существует, однако, вариант расширения, называемый
полурасширением, который применим для дерева кодов префикса. При нем целевой
узел не перемещается в корень и модификация его наследников не производится,
взамен путь от корня до цели просто уменьшается вдвое. Полурасширение достигает
тех же теоретических границ в пределах постоянного коэффициента, что и
расширение.
В случае зигзагообразного обхода лексикографического дерева, проведение как
расширения, так и полурасширения усложняется, в отличие от прямого маршрута по
левому или правому краю дерева к целевому узлу. Этот простой случай показан на
рисунке 2. Воздействие полурасширения на маршруте от корня (узел w) до листа
узла A заключается в перемене местами каждой пары внутренних следующих друг за
другом узлов, в результате чего длина пути от корня до узла-листа сокращается в
2 раза. В процессе полурасширения узлы каждой пары, более далекие от корня,
включаются в новый путь (узлы x и z), а более близкие из него
исключаются (узлы w и y).
Сохранение операцией полурасширения лексикографического порядка в деревьях кода
префикса не является обязательным. Единственно важным в операциях с кодом
префикса является точное соответствие дерева, используемого процедурой сжатия
дереву, используемому процедурой развертывания. Любое его изменение, допущенное
между последовательно идущими буквами, производится только в том случае, если
обе процедуры осуществляют одинаковые изменения в одинаковом порядке.
Hенужность поддержки лексикографического порядка значительно упрощает проведение
операции полурасширения за счет исключения случая зигзага. Это может быть
При записи или передаче данных часто бывает полезно сократить размер обрабатываемых данных. Технология, позволяющая достичь этой цели, называется сжатием данных. Существует множество методов сжатия данных, каждый из которых характеризуется собственной областью применения, в которой он дает наилучшие или, наоборот, наихудшие результаты.
Метод кодирования длины серий
Метод кодирования длины серий дает наилучшие результаты, если сжимаемые данные состоят из длинных последовательностей одних и тех же значений. В сущности, такой метод кодирования как раз и состоит в замене подобных последовательностей кодовым значением, определяющим повторяющееся значение и количество его повторений в данной серии. Например, для записи кодированной информации о том, что битовая последовательность состоит из 253 единиц, за которыми следуют 118 нулей и еще 87 единиц, потребуется существенно меньше места, чем для перечисления всех этих 458 бит.
Пример. Используя метод кодирования длины серий последовательность: 111111111100000000000000000 - можно представить в следующем виде: 10.
Метод относительного кодирования
В некоторых случаях информация может состоять из блоков данных, каждый из которых лишь немного отличается от предыдущего. Примером могут служить последовательные кадры видеоизображения. Для таких случаев используется метод относительного кодирования. Данный подход предполагает запись отличий, существующих между последовательными блоками данных, вместо записи самих этих блоков, т.е. каждый блок кодируется с точки зрения его взаимосвязи с предыдущим блоком.
Пример. Используя метод относительного кодирования, последовательность цифр: 1476; 1473; 1480; 1477 - можно представить в следующем виде: 1476; -3; +7; -3.
Частотно-зависимое кодирование
Этот метод сжатия данных предполагает применение частотно-зависимого кодирования, при котором длина битовой комбинации, представляющей элемент данных, обратно пропорциональна частоте использования этого элемента. Такие коды входят в группу кодов переменной длины, т.е. элементы данных в этих кодах представляются битовыми комбинациями различной длины. Если взять английский текст, закодированный с помощью частотно-зависимого метода, то чаще всего встречающиеся символы [е, t, а, i] будут представлены короткими битовыми комбинациями, а те знаки, которые встречаются реже , - более длинными битовыми комбинациями. В результате мы получим более короткое представление всего текста, чем при использовании обычного кода, подобного Unicode или ASCII. Построение алгоритма, который обычно используется при разработке частотно-зависимых кодов, приписывают Девиду Хаффману , поэтому такие коды часто называются кодами Хаффмана. Большинство используемых сегодня частотно-зависимых кодов является кодами Хаффмана.
Пример. Пусть требуется закодировать частотно-зависимым методом последовательность: αγααβααγααβαλααβαβαβαβαα, которая состоит из четырех символов α, β, γ и λ. Причем в этой последовательности α встречается 15 раз, β - 6 раз, γ - 2 раза и λ - 1 раз.
Выберем в соответствии с методом Хаффмана следующий двоичный код для представления символов:
α - 1
β - 01
γ - 001
λ - 000
Метод Лемпеля-Зива
Данный метод назван в честь его создателей, Абрахама Лемпеля и Джэкоба Зива . Системы кодирования по методу Лемпеля-Зива используют технологию кодирования с применением адаптивного словаря. В данном контексте термин словарь означает набор строительных блоков, из которых создается сжатое сообщение. Если сжатию подвергается английский текст, то строительными блоками могут быть символы алфавита. Если потребуется уменьшить размер данных, которые хранятся в компьютере, то компоновочными блоками могут стать нули и единицы. В процессе адаптивного словарного кодирования содержание словаря может изменяться. Например, при сжатии английского текста может оказаться целесообразным добавить в словарь окончание ing и артикль the. В этом случае место, занимаемое будущими копиями окончания ing и артикля the, может быть уменьшено за счет записи их как одиночных ссылок вместо сочетания из трех разных ссылок. Системы кодирования по методу Лемпеля-Зива используют изощренные и весьма эффективные методы адаптации словаря в процессе кодирования или сжатия. В частности, в любой момент процесса кодирования словарь будет состоять из тех комбинаций, которые уже были закодированы [сжаты].
В качестве примера рассмотрим, как можно выполнить сжатие сообщения с использованием конкретной системы метода Лемпеля-Зива, известной как LZ77. Процесс начинается практически с переписывания начальной части сообщения, однако в определенный момент осуществляется переход к представлению будущих сегментов с помощью триплетов, каждый из которых будет состоять из, двух целых чисел и следующего за ними одного символа текста. Каждый триплет описывает способ построения следующей части сообщения. Например, пусть распакованный текст имеет следующий вид:
αβααβλβ
Строка αβααβλβ является уже распакованной частью сообщения. Для того чтобы разархивировать остальной текст сообщения, необходимо сначала расширить строку, присоединив к ней ту часть, которая в ней уже встречается. Первый номер в триплете указывает, сколько символов необходимо отсчитать в обратном направлении в строке, чтобы найти первый символ добавляемого сегмента. В данном случае необходимо отсчитать в обратном направлении 5 символов, и мы попадем на второй слева символ а уже распакованной строки. Второе число в триплете задает количество последовательных символов справа от начального, которые составляют добавляемый сегмент. В нашем примере это число 4, и это означает, что добавляемым сегментом будет ααβλ. Копируем его в конец строки и получаем новое значение распакованной части сообщения: αβααβλβααβλ.
Наконец, последний элемент [в нашем случае это символ α] должен быть помещен в конец расширенной строки, в результате чего получаем полностью распакованное сообщение: αβααβλβααβλα.
Сжатие изображений
Растровый формат, используемый в современных цифровых преобразователях изображений, предусматривает кодирование изображения в формате по три байта на пиксель, что приводит к созданию громоздких, неудобных в работе растровых файлов. Специально для этого формата было разработано множество схем сжатия, предназначенных для уменьшения места, занимаемого подобными файлами на диске. Одной из таких схем является формат GIF , разработанный компанией CompuServe. Используемый в ней метод заключается в уменьшении количества цветовых оттенков пикселя до 256, в результате чего цвет каждого пикселя может быть представлен одним байтом вместо трех. С помощью таблицы, называемой цветовой палитрой, каждый из допустимых цветовых оттенков пикселя ассоциируется с некоторой комбинацией цветов "красный-зеленый-синий". Изменяя используемую палитру, можно изменять цвета, появляющиеся в изображении.
Обычно один из цветов палитры в формате GIF воспринимается как обозначение "прозрачности". Это означает, что в закрашенных этим цветом участках изображения отображается цвет того фона, на котором оно находится. Благодаря этому и относительной простоте использования изображений формат GIF получил широкое распространение в тех компьютерных играх, где множество различных картинок перемещается по экрану.
Другим примером системы сжатия изображений является формат JPEG. Это стандарт, разработанный ассоциацией Joint Photographic Experts Group [отсюда и название этого стандарта] в рамках организации ISO. Формат JPEG показал себя как эффективный метод представления цветных фотографий. Именно по этой причине данный стандарт используется производителями современных цифровых фотокамер. Следует ожидать, что он окажет немалое влияние на область цифрового представления изображений и в будущем.
В действительности стандарт JPEG включает несколько способов представления изображения, каждый из которых имеет собственное назначение. Например, когда требуется максимальная точность представления изображения, формат JPEG предлагает режим "без потерь", название которого прямо указывает, что процедура кодирования изображения будет выполнена без каких-либо потерь информации. В этом режиме экономия места достигается посредством запоминания различий между последовательными пикселями, а не яркости каждого пикселя в отдельности. Согласно теории, в большинстве случаев степень различия между соседними пикселями может быть закодирована более короткими битовыми комбинациями, чем собственно значения яркости отдельных пикселей. Существующие различия кодируются с помощью кода переменной длины, который применяется в целях дополнительного сокращения используемой памяти.
К сожалению, при использовании режима "без потерь" создаваемые файлы растровых изображений настолько велики, что они с трудом обрабатываются методами современной технологии, а потому и применяются на практике крайне редко. Большинство существующих приложений использует другой стандартный метод формата JPEG - режим "базовых строк". В этом режиме каждый из пикселей также представляется тремя составляющими, но в данном случае это уже один компонент яркости и два компонента цвета. Грубо говоря, если создать изображение только из компонентов яркости, то мы увидим черно-белый вариант изображения, так как эти компоненты отражают только уровень освещенности пикселя.
Смысл подобного разделения между цветом и яркостью объясняется тем, что человеческий глаз более чувствителен к изменениям яркости, чем цвета. Рассмотрим, например, два равномерно окрашенных синих прямоугольника, которые абсолютно идентичны, за исключением того, что на один из них нанесена маленькая яркая точка, тогда как на другой - маленькая зеленая точка той же яркости, что и синий фон. Глазу проще будет обнаружить яркую точку, а не зеленую. Режим "базовых строк" стандарта JPEG использует эту особенность, кодируя компонент яркости каждого пикселя, но усредняя значение цветовых компонентов для блоков, состоящих из четырех пикселей, и записывая цветовые компоненты только для этих блоков. В результате окончательное представление изображения сохраняет внезапные перепады яркости, однако оставляет размытыми резкие изменения цвета. Преимущество этой схемы состоит в том, что каждый блок из четырех пикселей представлен только шестью значениями [четыре показателя яркости и два - цвета], а не двенадцатью, которые необходимы при использовании схемы из трех показателей на каждый пиксель.
Современные пользователи довольно часто сталкиваются с проблемой нехватки свободного пространства на жестком диске. Многие, в попытке освободить хоть немного свободного пространства, пытаются удалить с жесткого диска всю ненужную информацию. Более продвинутые пользователи используют для уменьшения объема данных особые алгоритмы сжатия. Несмотря на эффективность этого процесса, многие пользователи никогда о нем даже не слышали. Давайте же попробуем разобраться, что подразумевается под сжатием данных, какие алгоритмы для этого могут использоваться.
На сегодняшний день сжатие информации является достаточно важной процедурой, которая необходима каждому пользователю ПК. Сегодня любой пользователь может позволить себе приобрести современный накопитель данных, в котором предусмотрена возможность использования большого объема памяти. Подобные устройства, как правило, оснащаются высокоскоростными каналами для транслирования информации. Однако, стоит отметить, что с каждым годом объем необходимой пользователям информации становится все больше и больше. Всего $10$ лет назад объем стандартного видеофильма не превышал $700$ Мб. В настоящее время объем фильмов в HD-качестве может достигать нескольких десятков гигабайт.
Когда необходимо сжатие данных?
Не стоит многого ждать от процесса сжатия информации. Но все-таки встречаются ситуации, в которых сжатие информации бывает просто необходимым и крайне полезным. Рассмотрим некоторые из таких случаев.
Передача по электронной почте.
Очень часто бывают ситуации, когда нужно переслать большой объем данных по электронной почте. Благодаря сжатию можно существенно уменьшить размер передаваемых файлов. Особенно оценят преимущества данной процедуры те пользователи, которые используют для пересылки информации мобильные устройства.
Публикация данных на интернет -сайтах и порталах.
Процедура сжатия часто используется для уменьшения объема документов, используемых для публикации на различных интернет-ресурсах. Это позволяет значительно сэкономить на трафике.
Экономия свободного места на диске.
Когда нет возможности добавить в систему новые средства для хранения информации, можно использовать процедуру сжатия для экономии свободного пространства на диске. Бывает так, что бюджет пользователя крайне ограничен, а свободного пространства на жестком диске не хватает. Вот тут-то на помощь и приходит процедура сжатия.
Кроме перечисленных выше ситуаций, возможно еще огромное количество случаев, в которых процесс сжатия данных может оказаться очень полезным. Мы перечислили только самые распространенные.
Способы сжатия информации
Все существующие способы сжатия информации можно разделить на две основные категории. Это сжатие без потерь и сжатие с определенными потерями. Первая категория актуальна только тогда, когда есть необходимость восстановить данные с высокой точностью, не потеряв ни одного бита исходной информации. Единственный случай, в котором необходимо использовать именно этот подход, это сжатие текстовых документов.
В том случае, если нет особой необходимости в максимально точном восстановлении сжатой информации, необходимо предусмотреть возможность использования алгоритмов с определенными потерями при сжатии.
Сжатие без потери информации
Данные методы сжатия информации интересуют прежде всего, так как именно они применяются при передаче больших объемов информации по электронной почте, при выдаче выполненной работы заказчику или при создании резервных копий информации, хранящейся на компьютере. Эти методы сжатия информации не допускают потерю информации, поскольку в их основу положено лишь устранение ее избыточности, информация же имеет избыточность практически всегда, если бы последней не было, нечего было бы и сжимать.
Пример 1
Приведем простой пример. Русский язык включает в себя $33$ буквы, $10$ цифр и еще примерно $15$ знаков препинания и других специальных символов. Для текста, записанного только прописными русскими буквами (например как в телеграммах) вполне хватило бы $60$ разных значений. Тем не менее, каждый символ обычно кодируется байтом, содержащим, как нам известно, 8 битов, и может выражаться $256$ различными кодами. Это один из первых факторов, характеризующих избыточность. Для телеграфного текста вполне хватило бы и $6$ битов на символ.
Пример 2
Рассмотрим другой пример. В международной кодировке символов ASCII для кодирования любого символа выделяется одинаковое количество битов ($8$), в то время, как всем давно и хорошо известно, что наиболее часто встречающиеся символы имеет смысл кодировать меньшим количеством знаков. Так, к примеру, в азбуке Морзе буквы «Е» и «Т», которые встречаются очень часто, кодируются $1$ знаком (соответственно это точка и тире). А такие редкие буквы, как «Ю» ($ - -$) и «Ц» ($- - $), кодируются $4$ знаками.
Замечание 1
Неэффективная кодировка является вторым фактором, характеризующим избыточность. Программы, благодаря которым выполняется сжатие информации, могут вводить свою кодировку, причем она может быть разной для разных файлов, и приписывать ее к сжатому файлу в виде таблицы (словаря), из которой распаковывающая программа будет считывать информацию о том, как в данном файле закодированы те или иные символы или их группы.
Алгоритмы, в основу которых положено перекодирование информации, называются алгоритмами Хаффмана.
Алгоритм Хаффмана
В данном алгоритме сжатие информации осуществляется путем статистического кодирования или на основе словаря, который предварительно был создан. Согласно статистическому алгоритму Хаффмана каждому входному символу присваивается определенный код. При этом наиболее часто используемому символу - наиболее короткий код, а наиболее редко используемому - более длинный. В качестве примера на диаграмме приведено распределение частоты использования отдельных букв английского алфавита (рис.1). Такое распределение может быть построено и для русского языка. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти.
Рисунок 1. Распределение английских букв по их частоте использования
Величина сжатия определяется избыточностью обрабатываемого массива бит. Каждый из естественных языков обладает определенной избыточностью. Среди европейских языков русский имеет самый высокий уровней избыточности. Об этом можно судить по размерам русского перевода английского текста. Обычно он примерно на $30\%$ больше. Если речь идет о стихотворном тексте, избыточность может быть до $2$ раз выше.
Замечание 2
Самая большая сложность с кодами заключается в необходимости иметь таблицы вероятностей для каждого типа сжимаемых данных. Это не представляет проблемы, если известно, что сжимается английский или русский текст. В этом случае мы просто предоставляем кодеру и декодеру подходящее для английского или русского текста кодовое дерево. В общем же случае, когда вероятность символов для входных данных неизвестна, статические коды Хаффмана работают неэффективно.
Решением этой проблемы является статистический анализ кодируемых данных, выполняемый в ходе первого прохода по данным, и составление на его основе кодового дерева. Собственно кодирование при этом выполняется вторым проходом.
Еще одним недостатком кодов является то, что минимальная длина кодового слова для них не может быть меньше единицы, тогда как энтропия сообщения вполне может составлять и $0,1$, и $0,01$ бит/букву. В этом случае код становится существенно избыточным. Проблема решается применением алгоритма к блокам символов, но тогда усложняется процедура кодирования/декодирования и значительно расширяется кодовое дерево, которое нужно в конечном итоге сохранять вместе с кодом.
Данные коды никак не учитывают взаимосвязей между символами, которые присутствуют практически в любом тексте.
Замечание 3
Сегодня, в век информации, несмотря на то, что практически каждому пользователю доступны высокоскоростные каналы для передачи данных и носители больших объемов, вопрос сжатия данных остается актуальным. Существуют ситуации, в которых сжатие данных является просто необходимой операцией. В частности, это касается пересылки данных по электронной почте и размещения информации в Интернете.
GORKOFF 24 февраля 2015 в 11:41
Методы сжатия данных
- Алгоритмы
Мы с моим научным руководителем готовим небольшую монографию по обработке изображений. Решил представить на суд хабрасообщества главу, посвящённую алгоритмам сжатия изображений. Так как в рамках одного поста целую главу уместить тяжело, решил разбить её на три поста:
1. Методы сжатия данных;
2. Сжатие изображений без потерь;
3. Сжатие изображений с потерями.
Ниже вы можете ознакомиться с первым постом серии.
На текущий момент существует большое количество алгоритмов сжатия без потерь, которые условно можно разделить на две большие группы:
1. Поточные и словарные алгоритмы. К этой группе относятся алгоритмы семейств RLE (run-length encoding), LZ* и др. Особенностью всех алгоритмов этой группы является то, что при кодировании используется не информация о частотах символов в сообщении, а информация о последовательностях, встречавшихся ранее.
2. Алгоритмы статистического (энтропийного) сжатия. Эта группа алгоритмов сжимает информацию, используя неравномерность частот, с которыми различные символы встречаются в сообщении. К алгоритмам этой группы относятся алгоритмы арифметического и префиксного кодирования (с использованием деревьев Шеннона-Фанно, Хаффмана, секущих).
В отдельную группу можно выделить алгоритмы преобразования информации. Алгоритмы этой группы не производят непосредственного сжатия информации, но их применение значительно упрощает дальнейшее сжатие с использованием поточных, словарных и энтропийных алгоритмов.
Поточные и словарные алгоритмы
Кодирование длин серий
Кодирование длин серий (RLE - Run-Length Encoding) - это один из самых простых и распространённых алгоритмов сжатия данных. В этом алгоритме последовательность повторяющихся символов заменяется символом и количеством его повторов.Например, строку «ААААА», требующую для хранения 5 байт (при условии, что на хранение одного символа отводится байт), можно заменить на «5А», состоящую из двух байт. Очевидно, что этот алгоритм тем эффективнее, чем длиннее серия повторов.
Основным недостатком этого алгоритма является его крайне низкая эффективность на последовательностях неповторяющихся символов. Например, если рассмотреть последовательность «АБАБАБ» (6 байт), то после применения алгоритма RLE она превратится в «1А1Б1А1Б1А1Б» (12 байт). Для решения проблемы неповторяющихся символов существуют различные методы.
Самым простым методом является следующая модификация: байт, кодирующий количество повторов, должен хранить информацию не только о количестве повторов, но и об их наличии. Если первый бит равен 1, то следующие 7 бит указывают количество повторов соответствующего символа, а если первый бит равен 0, то следующие 7 бит показывают количество символов, которые надо взять без повтора. Если закодировать «АБАБАБ» с использованием данной модификации, то получим «-6АБАБАБ» (7 байт). Очевидно, что предложенная методика позволяет значительно повысить эффективность RLE алгоритма на неповторяющихся последовательностях символов. Реализация предложенного подхода приведена в Листинг 1:
- type
- function RLEEncode(InMsg: ShortString) : TRLEEncodedString;
- MatchFl: boolean ;
- MatchCount: shortint ;
- EncodedString: TRLEEncodedString;
- N, i: byte ;
- begin
- N : = 0 ;
- SetLength(EncodedString, 2 * length(InMsg) ) ;
- while length(InMsg) >= 1 do
- begin
- MatchFl : = (length(InMsg) > 1 ) and (InMsg[ 1 ] = InMsg[ 2 ] ) ;
- MatchCount : = 1 ;
- while (MatchCount <= 126 ) and (MatchCount < length(InMsg) ) and ((InMsg[ MatchCount] = InMsg[ MatchCount + 1 ] ) = MatchFl) do
- MatchCount : = MatchCount + 1 ;
- if MatchFl then
- begin
- N : = N + 2 ;
- EncodedString[ N - 2 ] : = MatchCount + 128 ;
- EncodedString[ N - 1 ] : = ord (InMsg[ 1 ] ) ;
- else
- begin
- if MatchCount <> length(InMsg) then
- MatchCount : = MatchCount - 1 ;
- N : = N + 1 + MatchCount;
- EncodedString[ N - 1 - MatchCount] : = - MatchCount + 128 ;
- for i : = 1 to MatchCount do
- EncodedString[ N - 1 - MatchCount + i] : = ord (InMsg[ i] ) ;
- end ;
- delete(InMsg, 1 , MatchCount) ;
- end ;
- SetLength(EncodedString, N) ;
- RLEEncode : = EncodedString;
- end ;
Декодирование сжатого сообщения выполняется очень просто и сводится к однократному проходу по сжатому сообщению см. Листинг 2:
- type
- TRLEEncodedString = array of byte ;
- function RLEDecode(InMsg: TRLEEncodedString) : ShortString;
- RepeatCount: shortint ;
- i, j: word ;
- OutMsg: ShortString;
- begin
- OutMsg : = "" ;
- i : = 0 ;
- while i < length(InMsg) do
- begin
- RepeatCount : = InMsg[ i] - 128 ;
- i : = i + 1 ;
- if RepeatCount < 0 then
- begin
- RepeatCount : = abs (RepeatCount) ;
- for j : = i to i + RepeatCount - 1 do
- OutMsg : = OutMsg + chr (InMsg[ j] ) ;
- i : = i + RepeatCount;
- else
- begin
- for j : = 1 to RepeatCount do
- OutMsg : = OutMsg + chr (InMsg[ i] ) ;
- i : = i + 1 ;
- end ;
- end ;
- RLEDecode : = OutMsg;
- end ;
Вторым методом повышения эффективности алгоритма RLE является использование алгоритмов преобразования информации, которые непосредственно не сжимают данные, но приводят их к виду, более удобному для сжатия. В качестве примера такого алгоритма мы рассмотрим BWT-перестановку, названную по фамилиям изобретателей Burrows-Wheeler transform. Эта перестановка не изменяет сами символы, а изменяет только их порядок в строке, при этом повторяющиеся подстроки после применения перестановки собираются в плотные группы, которые гораздо лучше сжимаются с помощью алгоритма RLE. Прямое BWT преобразование сводится к последовательности следующих шагов:
1. Добавление к исходной строке специального символа конца строки, который нигде более не встречается;
2. Получение всех циклических перестановок исходной строки;
3. Сортировка полученных строк в лексикографическом порядке;
4. Возвращение последнего столбца полученной матрицы.
Реализация данного алгоритма приведена в Листинг 3.
- const
- EOMsg = "|" ;
- function BWTEncode(InMsg: ShortString) : ShortString;
- OutMsg: ShortString;
- LastChar: ANSIChar;
- N, i: word ;
- begin
- InMsg : = InMsg + EOMsg;
- N : = length(InMsg) ;
- ShiftTable[ 1 ] : = InMsg;
- for i : = 2 to N do
- begin
- LastChar : = InMsg[ N] ;
- InMsg : = LastChar + copy(InMsg, 1 , N - 1 ) ;
- ShiftTable[ i] : = InMsg;
- end ;
- Sort(ShiftTable) ;
- OutMsg : = "" ;
- for i : = 1 to N do
- OutMsg : = OutMsg + ShiftTable[ i] [ N] ;
- BWTEncode : = OutMsg;
- end ;
Проще всего пояснить это преобразование на конкретном примере. Возьмём строку «АНАНАС» и договоримся, что символом конца строки будет символ «|». Все циклические перестановки этой строки и результат их лексикографической сортировки приведены в Табл. 1.

Т.е. результатом прямого преобразования будет строка «|ННАААС». Легко заметить, что это строка гораздо лучше, чем исходная, сжимается алгоритмом RLE, т.к. в ней существуют длинные подпоследовательности повторяющихся букв.
Подобного эффекта можно добиться и с помощью других преобразований, но преимущество BWT-преобразования в том, что оно обратимо, правда, обратное преобразование сложнее прямого. Для того, чтобы восстановить исходную строку, необходимо выполнить следующие действия:
Создать пустую матрицу размером n*n, где n-количество символов в закодированном сообщении;
Заполнить самый правый пустой столбец закодированным сообщением;
Отсортировать строки таблицы в лексикографическом порядке;
Повторять шаги 2-3, пока есть пустые столбцы;
Вернуть ту строку, которая заканчивается символом конца строки.
Реализация обратного преобразования на первый взгляд не представляет сложности, и один из вариантов реализации приведён в Листинг 4.
- const
- EOMsg = "|" ;
- function BWTDecode(InMsg: ShortString) : ShortString;
- OutMsg: ShortString;
- ShiftTable: array of ShortString;
- N, i, j: word ;
- begin
- OutMsg : = "" ;
- N : = length(InMsg) ;
- SetLength(ShiftTable, N + 1 ) ;
- for i : = 0 to N do
- ShiftTable[ i] : = "" ;
- for i : = 1 to N do
- begin
- for j : = 1 to N do
- ShiftTable[ j] : = InMsg[ j] + ShiftTable[ j] ;
- Sort(ShiftTable) ;
- end ;
- for i : = 1 to N do
- if ShiftTable[ i] [ N] = EOMsg then
- OutMsg : = ShiftTable[ i] ;
- delete(OutMsg, N, 1 ) ;
- BWTDecode : = OutMsg;
- end ;
Но на практике эффективность зависит от выбранного алгоритма сортировки. Тривиальные алгоритмы с квадратичной сложностью, очевидно, крайне негативно скажутся на быстродействии, поэтому рекомендуется использовать эффективные алгоритмы.

После сортировки таблицы, полученной на седьмом шаге, необходимо выбрать из таблицы строку, заканчивающуюся символом «|». Легко заметить, что это строка единственная. Т.о. мы на конкретном примере рассмотрели преобразование BWT.
Подводя итог, можно сказать, что основным плюсом группы алгоритмов RLE является простота и скорость работы (в том числе и скорость декодирования), а главным минусом является неэффективность на неповторяющихся наборах символов. Использование специальных перестановок повышает эффективность алгоритма, но также сильно увеличивает время работы (особенно декодирования).
Словарное сжатие (алгоритмы LZ)
Группа словарных алгоритмов, в отличие от алгоритмов группы RLE, кодирует не количество повторов символов, а встречавшиеся ранее последовательности символов. Во время работы рассматриваемых алгоритмов динамически создаётся таблица со списком уже встречавшихся последовательностей и соответствующих им кодов. Эту таблицу часто называют словарём, а соответствующую группу алгоритмов называют словарными.Ниже описан простейший вариант словарного алгоритма:
Инициализировать словарь всеми символами, встречающимися во входной строке;
Найти в словаре самую длинную последовательность (S), совпадающую с началом кодируемого сообщения;
Выдать код найденной последовательности и удалить её из начала кодируемого сообщения;
Если не достигнут конец сообщения, считать очередной символ и добавить Sc в словарь, перейти к шагу 2. Иначе, выход.
Например, только что инициализированный словарь для фразы «КУКУШКАКУКУШОНКУКУПИЛАКАПЮШОН» приведён в Табл. 3:

В процессе сжатия словарь будет дополняться встречающимися в сообщении последовательностями. Процесс пополнения словаря приведён в Табл. 4.

При описании алгоритма намеренно было опущено описание ситуации, когда словарь заполняется полностью. В зависимости от варианта алгоритма возможно различное поведение: полная или частичная очистка словаря, прекращение заполнение словаря или расширение словаря с соответствующим увеличением разрядности кода. Каждый из этих подходов имеет определённые недостатки. Например, прекращение пополнения словаря может привести к ситуации, когда в словаре хранятся последовательности, встречающиеся в начале сжимаемой строки, но не встречающиеся в дальнейшем. В то же время очистка словаря может привести к удалению частых последовательностей. Большинство используемых реализаций при заполнении словаря начинают отслеживать степень сжатия, и при её снижении ниже определённого уровня происходит перестройка словаря. Далее будет рассмотрена простейшая реализация, прекращающая пополнение словаря при его заполнении.
Для начала определим словарь как запись, хранящую не только встречавшиеся подстроки, но и количество хранящихся в словаре подстрок:
Встречавшиеся ранее подпоследовательности хранятся в массиве Words, а их кодом являются номера подпоследовательностей в этом массиве.
Также определим функции поиска в словаре и добавления в словарь:
- const
- MAX_DICT_LENGTH = 256 ;
- function FindInDict(D: TDictionary; str: ShortString) : integer ;
- r: integer ;
- i: integer ;
- fl: boolean ;
- begin
- r : = - 1 ;
- if D. WordCount > 0 then
- begin
- i : = D. WordCount ;
- fl : = false ;
- while (not fl) and (i >= 0 ) do
- begin
- i : = i - 1 ;
- fl : = D. Words [ i] = str;
- end ;
- end ;
- if fl then
- r : = i;
- FindInDict : = r;
- end ;
- procedure AddToDict(var D: TDictionary; str: ShortString) ;
- begin
- if D. WordCount < MAX_DICT_LENGTH then
- begin
- D. WordCount : = D. WordCount + 1 ;
- SetLength(D. Words , D. WordCount ) ;
- D. Words [ D. WordCount - 1 ] : = str;
- end ;
- end ;
Используя эти функции, процесс кодирования по описанному алгоритму можно реализовать следующим образом:
- function LZWEncode(InMsg: ShortString) : TEncodedString;
- OutMsg: TEncodedString;
- tmpstr: ShortString;
- D: TDictionary;
- i, N: byte ;
- begin
- SetLength(OutMsg, length(InMsg) ) ;
- N : = 0 ;
- InitDict(D) ;
- while length(InMsg) > 0 do
- begin
- tmpstr : = InMsg[ 1 ] ;
- while (FindInDict(D, tmpstr) >= 0 ) and (length(InMsg) > length(tmpstr) ) do
- tmpstr : = tmpstr + InMsg[ length(tmpstr) + 1 ] ;
- if FindInDict(D, tmpstr) < 0 then
- delete(tmpstr, length(tmpstr) , 1 ) ;
- OutMsg[ N] : = FindInDict(D, tmpstr) ;
- N : = N + 1 ;
- delete(InMsg, 1 , length(tmpstr) ) ;
- if length(InMsg) > 0 then
- AddToDict(D, tmpstr + InMsg[ 1 ] ) ;
- end ;
- SetLength(OutMsg, N) ;
- LZWEncode : = OutMsg;
- end ;
Результатом кодирования будут номера слов в словаре.
Процесс декодирования сводится к прямой расшифровке кодов, при этом нет необходимости передавать созданный словарь, достаточно, чтобы при декодировании словарь был инициализирован так же, как и при кодировании. Тогда словарь будет полностью восстановлен непосредственно в процессе декодирования путём конкатенации предыдущей подпоследовательности и текущего символа.
Единственная проблема возможна в следующей ситуации: когда необходимо декодировать подпоследовательность, которой ещё нет в словаре. Легко убедиться, что это возможно только в случае, когда необходимо извлечь подстроку, которая должна быть добавлена на текущем шаге. А это значит, что подстрока удовлетворяет шаблону cSc, т.е. начинается и заканчивается одним и тем же символом. При этом cS – это подстрока, добавленная на предыдущем шаге. Рассмотренная ситуация – единственная, когда необходимо декодировать ещё не добавленную строку. Учитывая вышесказанное, можно предложить следующий вариант декодирования сжатой строки:
- function LZWDecode(InMsg: TEncodedString) : ShortString;
- D: TDictionary;
- OutMsg, tmpstr: ShortString;
- i: byte ;
- begin
- OutMsg : = "" ;
- tmpstr : = "" ;
- InitDict(D) ;
- for i : = 0 to length(InMsg) - 1 do
- begin
- if InMsg[ i] >= D. WordCount then
- tmpstr : = D. Words [ InMsg[ i - 1 ] ] + D. Words [ InMsg[ i - 1 ] ] [ 1 ]
- else
- tmpstr : = D. Words [ InMsg[ i] ] ;
- OutMsg : = OutMsg + tmpstr;
- if i > 0 then
- AddToDict(D, D. Words [ InMsg[ i - 1 ] ] + tmpstr[ 1 ] ) ;
- end ;
- LZWDecode : = OutMsg;
- end ;
К плюсам словарных алгоритмов относится их большая по сравнению с RLE эффективность сжатия. Тем не менее надо понимать, что реальное использование этих алгоритмов сопряжено с некоторыми трудностями реализации.
Энтропийное кодирование
Кодирование с помощью деревьев Шеннона-Фано
Алгоритм Шеннона-Фано - один из первых разработанных алгоритмов сжатия. В основе алгоритма лежит идея представления более частых символов с помощью более коротких кодов. При этом коды, полученные с помощью алгоритма Шеннона-Фано, обладают свойством префиксности: т.е. ни один код не является началом никакого другого кода. Свойство префиксности гарантирует, что кодирование будет взаимно-однозначным. Алгоритм построения кодов Шеннона-Фано представлен ниже:1. Разбить алфавит на две части, суммарные вероятности символов в которых максимально близки друг к другу.
2. В префиксный код первой части символов добавить 0, в префиксный код второй части символов добавить 1.
3. Для каждой части (в которой не менее двух символов) рекурсивно выполнить шаги 1-3.
Несмотря на сравнительную простоту, алгоритм Шеннона-Фано не лишён недостатков, самым существенным из которых является неоптимальность кодирования. Хоть разбиение на каждом шаге и является оптимальным, алгоритм не гарантирует оптимального результата в целом. Рассмотрим, например, следующую строку: «ААААБВГДЕЖ». Соответствующее дерево Шеннона-Фано и коды, полученные на его основе, представлены на Рис. 1:

Без использования кодирования сообщение будет занимать 40 бит (при условии, что каждый символ кодируется 4 битами), а с использованием алгоритма Шеннона-Фано 4*2+2+4+4+3+3+3=27 бит. Объём сообщения уменьшился на 32.5%, но ниже будет показано, что этот результат можно значительно улучшить.
Кодирование с помощью деревьев Хаффмана
Алгоритм кодирования Хаффмана, разработанный через несколько лет после алгоритма Шеннона-Фано, тоже обладает свойством префиксности, а, кроме того, доказанной минимальной избыточностью, именно этим обусловлено его крайне широкое распространение. Для получения кодов Хаффмана используют следующий алгоритм:1. Все символы алфавита представляются в виде свободных узлов, при этом вес узла пропорционален частоте символа в сообщении;
2. Из множества свободных узлов выбираются два узла с минимальным весом и создаётся новый (родительский) узел с весом, равным сумме весов выбранных узлов;
3. Выбранные узлы удаляются из списка свободных, а созданный на их основе родительский узел добавляется в этот список;
4. Шаги 2-3 повторяются до тех пор, пока в списке свободных больше одного узла;
5. На основе построенного дерева каждому символу алфавита присваивается префиксный код;
6. Сообщение кодируется полученными кодами.
Рассмотрим тот же пример, что и в случае с алгоритмом Шеннона-Фано. Дерево Хаффмана и коды, полученные для сообщения «ААААБВГДЕЖ», представлены на Рис. 2:

Легко подсчитать, что объём закодированного сообщения составит 26 бит, что меньше, чем в алгоритме Шеннона-Фано. Отдельно стоит отметить, что ввиду популярности алгоритма Хаффмана на данный момент существует множество вариантов кодирования Хаффмана, в том числе и адаптивное кодирование, которое не требует передачи частот символов.
Среди недостатков алгоритма Хаффмана значительную часть составляют проблемы, связанные со сложностью реализации. Использование для хранения частот символов вещественных переменных сопряжено с потерей точности, поэтому на практике часто используют целочисленные переменные, но, т.к. вес родительских узлов постоянно растёт, рано или поздно возникает переполнение. Т.о., несмотря на простоту алгоритма, его корректная реализация до сих пор может вызывать некоторые затруднения, особенно для больших алфавитов.
Кодирование с помощью деревьев секущих функций
Кодирование с помощью секущих функций – разработанный авторами алгоритм, позволяющий получать префиксные коды. В основе алгоритма лежит идея построения дерева, каждый узел которого содержит секущую функцию. Чтобы подробнее описать алгоритм, необходимо ввести несколько определений.Слово – упорядоченная последовательность из m бит (число m называют разрядностью слова).
Литерал секущей – пара вида разряд-значение разряда. Например, литерал (4,1) означает, что 4 бит слова должен быть равен 1. Если условие литерала выполняется, то литерал считается истинным, в противном случае - ложным.
k-разрядной секущей называют множество из k литералов. Если все литералы истинны, то и сама секущая функция истинная, в противном случае она ложная.
Дерево строится так, чтобы каждый узел делил алфавит на максимально близкие части. На Рис. 3 показан пример дерева секущих:

Дерево секущих функций в общем случае не гарантирует оптимального кодирования, но зато обеспечивает крайне высокую скорость работы за счёт простоты операции в узлах.
Арифметическое кодирование
Арифметическое кодирование – один из наиболее эффективных способов сжатия информации. В отличие от алгоритма Хаффмана арифметическое кодирование позволяет кодировать сообщения с энтропией меньше 1 бита на символ. Т.к. большинство алгоритмов арифметического кодирования защищены патентами, далее будут описаны только основные идеи.Предположим, что в используемом алфавите N символов a_1,…,a_N, с частотами p_1,…,p_N, соответственно. Тогда алгоритм арифметического кодирования будет выглядеть следующим образом:
В качестве рабочего полуинтервала взять }